8 network automation tasks for anyone to get started
Automating your network can be daunting, but the payoff is huge. Here are eight easy automation tasks to help any network engineer get started.

The article outlines an eight-step practical roadmap for network engineers to adopt infrastructure as code and network automation, addressing common trepidation by focusing on achievable tasks and free tools. It describes a technical environment that includes Git, GitHub, Linux/WSL, VS Code with extensions, REST APIs, and Postman, and emphasizes operational impacts such as reduced human error, greater agility, secure credential handling, accurate inventory and data models, templated intent with Jinja2, and idempotent configuration deployment. Key outcomes include safer automation adoption through gradual steps—tooling, vaulting secrets, inventorying, secure connectivity, information gathering, data modeling, templating, and finally automated, idempotent deployments tied to CI/CD workflows.
What foundational tools does the article recommend as a minimum toolkit for getting started with network automation?
The article recommends several free, foundational tools: Git for version and source control and a Git repository such as GitHub for centralized storage; a Linux environment (or Windows Subsystem for Linux with Ubuntu) because most IaC tools require Linux; Visual Studio Code (VS Code) as the preferred editor/IDE, enhanced with extensions like Better Jinja, Docker, GitLens, Jinja2 Snippet Kit, Live Share, Markdownlint, PowerShell, and Python; familiarity with REST APIs and JSON/XML as the modern interface to infrastructure; and Postman for exploring and scripting REST APIs. These components form the minimal, practical toolkit before adopting higher-level automation frameworks.
Why does the author stress vaulting credentials early in the automation journey and what guidance is provided?
The author warns that network automation often falls into the trap of building functionality first and securing it later, which risks exposing credentials in source control. The guidance is to make secrets management an early priority: use vault mechanisms available in tooling (e.g., Ansible vault, Azure vault options) or secret handling features in scripts (for example, secret strings in Python) so credentials are encrypted from the outset. The takeaway is to avoid storing plain credentials in repositories and ensure encryption before scaling automation to prevent accidental credential leakage.
How do inventory files, data models, and Jinja2 templates work together to achieve idempotent network configuration?
According to the article, inventory files (hosts) capture and hierarchically organize all targets—routers, switches, firewalls, servers, SANs, and APIs—by platform, function, or location. From captured network state, you build YAML data models for individual devices (hostname, IP, device-specific attributes) and groups (shared credentials or attributes). Jinja2 templates represent desired configuration intent with variables, conditionals, and loops. Combining a device/group data model with Jinja2 templates generates the intended configuration. Pushing that compiled intent to targets and using CI/CD-driven build and release processes establishes idempotency between repository intent and running configuration, enabling programmatic CRUD operations and repeatable, scaleable deployments.
Network automation and the broader, rapidly evolving infrastructure-as-code approach to solving problems may seem daunting. Terrifying, even. Individuals and entire enterprises alike feel trepidation when trying to adopt this new methodology.
But automation has real value. It makes your network agile, significantly reduces human errors, and gives machine intelligence a seat at the table. Infrastructure as code easily provides the highest return on investment in the networking industry today.
The payoff for even just starting on this journey is massive. Why? Because all of the tools you need to build these fancy automated solutions are free.
Using my five-year journey with infrastructure as code as a guide, below are my top eight recommendations for network automation tasks that any network engineer can start with.
8. Build your toolkit
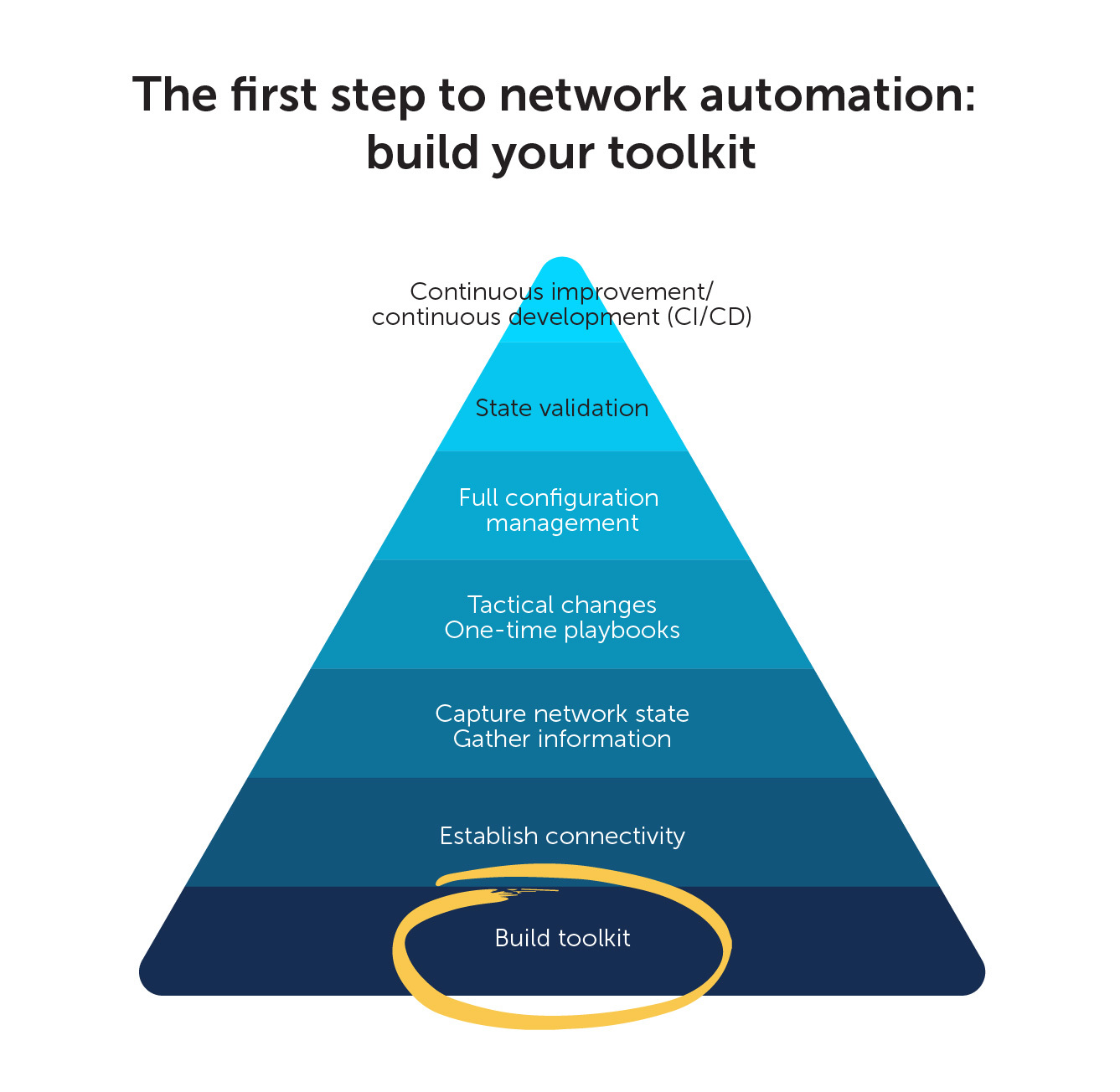
To be successful with network automation, there are some tools you must integrate into your toolkit and everyday work habits. These are not necessarily tools like Ansible, Chef, Puppet, or Terraform. Instead, they are lower-level—and admittedly not as enticing—tools like your integrated development environment (IDE) and version or source control system.
And, again, all of them are free. Below is a list of tools you should start using now.
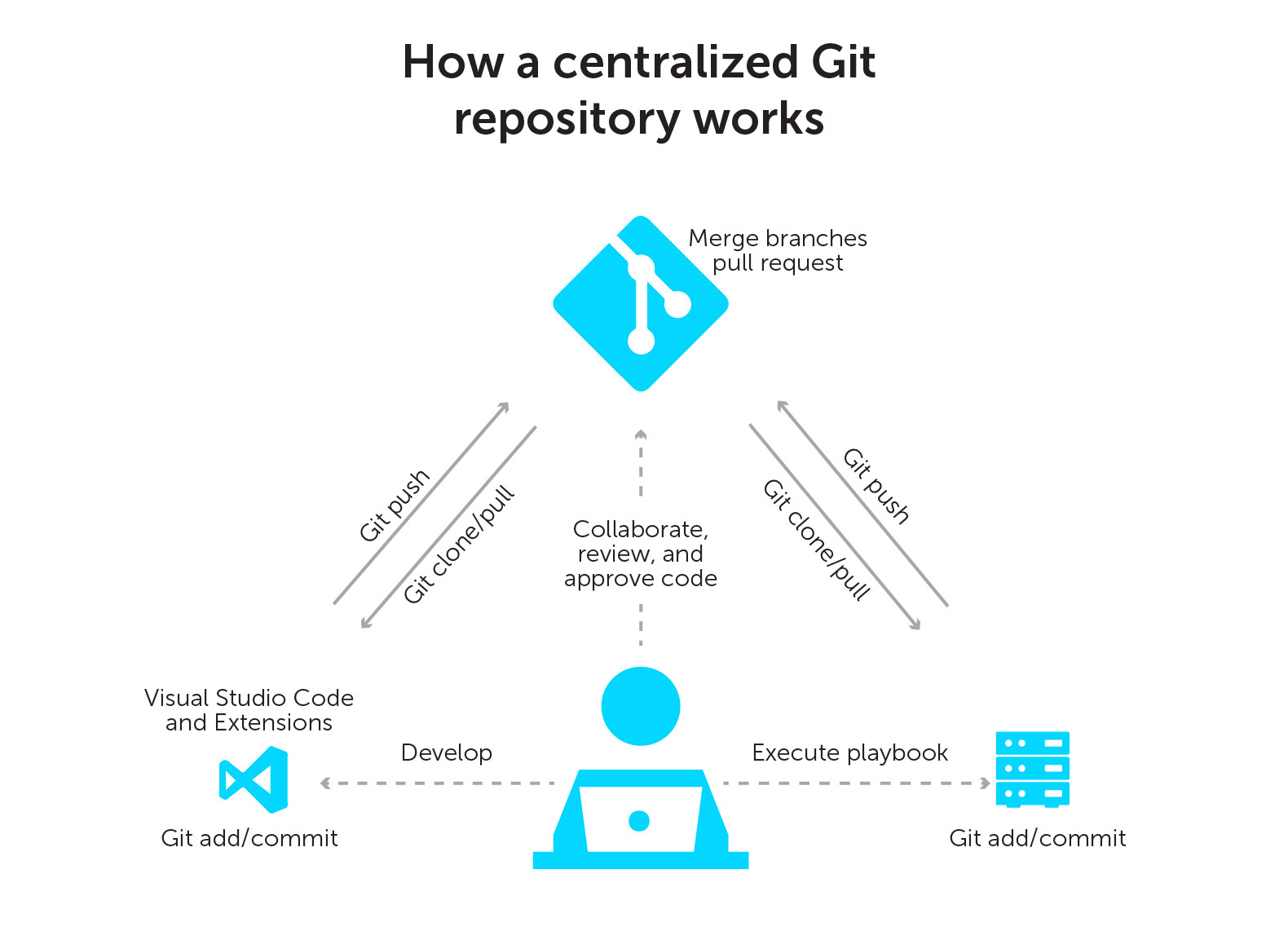
Git: Infrastructure as code is not just a buzzword. It is an approach to solving infrastructure problems programmatically. As such, you will want to control the source code as well as provide a versioning system. Enter Git.
- The open-source industry standard for version and source control.
- Start with Learn Git Branching and end up at Oh Shit Git!?!
A Git repository: Now that you have a source- and version-controlled set of code, you need somewhere to keep it. GitHub offers a centralized and open repository system. In fact, it is the largest collection of code in the world!
- If you do not already have a GitHub account, go make one.
- While you are exploring GitHub, please star some of my Automate Your Network open-source projects!
Linux: The open-source operating system driven by the command-line interface (CLI). Most infrastructure-as-code tools will only work in a Linux environment.
- Yes, Linux. Tools like Ansible only support Linux.
- Enabling the Windows Subsystem for Linux (WSL) is a great way to start learning and using Linux.
- Then, download Ubuntu from the Microsoft Store.
- Now you have the best of both worlds in the same workstation!
Visual Studio (VS) Code: An enhanced text editor. But I would go so far as to call it a full-blown IDE.
- VS Code is the defacto standard and, in my opinion, the absolute best enhanced text editor and IDE.
- Git-integrated, GitHub-integrated, and WSL-integrated.
- Type code . in Ubuntu to launch VS Code in Windows and allow for editing your WSL Linux-local files.
- Read that again. Yes, you can do this!
VS Code Extensions: If you can imagine, the base functionality of VS Code can be enhanced further and customized to support every programming language and framework available. VS Code extensions actually help you write your code!
- There are hundreds—maybe thousands—of extensions you can use to enhance VS Code’s already amazing base functionality.
- Some of my favorites for infrastructure as code:
- Better Jinja
- Docker
- Excel Viewer
- GitLens (this one is particularly good as it brings Git metadata into your editor’s features)
- Jinja2 Snippet Kit
- Live Share Extension Pack
- Pair or group program as a team inside one editor.
- Send a URL to your editing session and collaborate live in VS Code.
- Read that again.
- Markdown Preview Enhanced
- Markdownlint
- Open in Default Browser
- PowerShell
- Python
- VS Code Icons
REST APIs: Representational state transfer application programming interfaces (REST APIs) are the foundation of infrastructure as code. They allow humans to ‘speak’ to computers via an interface that accepts JavaScript Object Notation (JSON) or eXtensible Markup Language (XML).
- Every modern infrastructure component will come with a REST API.
- This is the new CLI.
- You had better get comfortable with JSON and fast.
Postman: You will need a way to consume the many REST APIs in your enterprise. Postman is an easy-to-use graphical user interface (GUI) to both consume APIs and program against them.
- Postman is poised to become the next Putty or Internet Explorer.
- Allows for easy REST API browsing (HTTP GET).
- Not to be reduced or classified as a simple tool.
- Pre-tests and post-tests in JavaScript
- Interactive console()
- A true REST API development kit
The above toolkit is what you will need to get started at a bare minimum. That’s without even delving into automation frameworks like Ansible or Python. There are significant learning curves involved with some of these tools because of complexity (Git) or the vast amount of capabilities (VS Code). Others, such as Postman, are more intuitive. Start using these tools now!
7. Vault your credentials
Network automation can fall into the classic trap of making it work and securing it later. I suggest taking a different approach. Secure your automation upfront and make it one of the first things you figure out if you are new to infrastructure as code. There are different vault mechanisms in Ansible and Azure or secret strings in Python. Either way, make sure your credentials are encrypted. Otherwise, they will end up in a Git repository someday.
6. Record your inventory
Automation and orchestration require targets, whether groups or individual hosts. Likely, you have many hosts. These include routers, switches, firewalls, load balancers, Windows/Linux/VMware (host and guest), SAN targets, and APIs. You must make sense of all of this in your hosts or inventory YAML dictionary files, ideally in a multi-tiered hierarchy. You can do so by platform, function, or location—any or all combinations work. This well-structured data model of your topology can then help guide and scope downstream automation.
5. Establish secure connectivity
It might sound trivial, but there are many ways to connect to modern infrastructure. Are you going to use SSH? WinRM? HTTPS? Do you have all of the required DNS entries? Can your potential Docker container image actually resolve to the targeted infrastructure? How are you going to handle DNS in this containerized world? What about air gap requirements, proxies, and firewall rules or routing flows?
After all, this is still network automation. Your network needs to be prepared.
4. Gather information
Once you have satisfied the above bootstrapping requirements, do not fall into the classic trap of leaping right to configuration management. As tempting as it is, refrain from making immediate changes to your network state with your new toys.
First, you must eliminate your risks. Begin by automating safe and simple—but highly valuable—show commands or HTTP GET requests to capture and document your current state.
Network data is your new oil. Now, you can tap into the source, refine it, and consume it as fuel for your enterprise.
You can safely start by gathering information for anything with an Ansible Facts/Info module or anything with a REST API. Start with the highest value propositions—your core, your data center, your BlueCat Address Manager. Go start your source of truth.
3. Build data models
Now that you have captured the network state, you can start to think about correcting, redesigning, or adjusting the configurations.
But before you jump into one-off tactical configuration changes without direction or focus, you should take the time to model the devices into YAML data models. You can use your inventory files to build data models at the group level (devices with commonalities based, again, on your inventory hierarchy) and for individual devices. The latter will contain things like the hostname, IP address, and other device-specific information. Meanwhile, groups of devices will likely share credentials or other common attributes.
These data models will be half of the equation to achieving fully automated configuration management and state validation.
2. Create template intent
The other half of the configuration management and state validation equation is Jinja2 templates. These templates are skeleton outlines of the desired state configuration with placeholders for dynamic data in the form of variables. Jinja2 templates can be simple or complex. They will often contain “if then else” conditional logic and “for loops” for iteration. Compiling the data model information with the automation tool of choice generates an intended configuration.
1. Establish idempotent configurations
Finally, having done all the other steps, you can now push those intended configurations to your target hosts.
Ideally, if all goes well, you have now established idempotency between your Git repository intended configuration and the actual running configuration of the target host. As a result, all future network changes and CRUD (create, read, update, and delete) activities can be done programmatically, either by adjusting the data model or the Jinja2 template.
You can recompile and push your intent using software build and release mechanisms, triggered by Git actions. These mechanisms use continuous integration and continuous deployment to execute Docker containers. Ultimately, they connect to your fabric and release the updates to the configuration, at scale, automatically.
Hungry for more? Be sure to check out my post on the 10 best Ansible modules for infrastructure as code that anyone—from a beginner to a power user—can leverage to transform their network.
Published in:

John Capobianco is the Senior IT Planner and Integrator for the House of Commons, Parliament of Canada. He is a 20-year IT professional who has fallen in love with automation and infrastructure as code. John maintains his CCNA, 2x CCNP, 5x Cisco Specialist, and Microsoft Certified ITP: Enterprise Administrator while continuously developing his programming and automation skills. He authors books and an automation-themed blog, automateyournetwork.ca. Find him on Twitter @john_capobianco or LinkedIn /john-capobianco-644a1515.
Related content

We bet on Intelligent NetOps two years ago. Infoblox now has too.
With Infoblox acquiring Kentik, BlueCat’s CEO confirms its vision for a single platform unifying DDI, network monitoring, and observability.

BlueCat DDI data boosts Cisco Cloud Control AI-driven operations
BlueCat’s integration with Cisco Cloud Control provides AI agents with access to trusted DDI data for network investigation and remediation.

Automate your DDI modernization path by migrating with Micetro
Automate cross-platform DNS and DHCP migration with Micetro to reduce risk, eliminate manual effort, and modernize infrastructure faster.

How to map your network with user-defined links in Integrity X
Map your network with user-defined links in Integrity X to define and manage custom relationships, such as dual-stack and NAT environments.