Banish network downtime with DNS high availability
If you have just one DNS server, what happens if it fails? Four avenues to DNS high availability are the key to a redundant and resilient network.

The article explains why a single DNS server is a single point of failure and describes a layered approach to DNS high availability to prevent network and website outages. It presents four complementary avenues—redundant hardware (xHA failover pairs), DNS protocol redundancy, distributed enterprise architecture, and integration with load balancers—to create an overlapping safety net that reduces downtime and meets availability SLAs. The piece also covers how BlueCat’s platform (including Address Manager) distributes DNS records across clusters and can limit human errors via access and change controls to prevent cascading failures.
What are the four avenues to achieve DNS high availability described in the article?
The article identifies four complementary avenues: 1) Hardware redundancy using an xHA (crossover high availability) approach where a backup server in the same physical location automatically takes over via failover; 2) DNS protocol redundancy, where clients automatically try another DNS server if one doesn’t respond; 3) Enterprise architecture that distributes services and ensures other servers can respond even if one location or server fails; and 4) Integration with third-party load balancers that perform health checks and redirect traffic to healthy servers. Implemented together, these form an overlapping, comprehensive solution.
How does BlueCat’s platform ensure DNS records remain available across the enterprise?
BlueCat’s platform uses Address Manager as the central repository for managed DNS information and pushes that data downstream to all master servers in the environment. Clusters of servers are interwoven so each cluster knows about the others; when records change they are sent to additional clusters upstream, enabling DNS responses from anywhere in the enterprise. This distributed replication and the persistent path between a user’s computer and the central repository help ensure record reachability and prevent data loss, even if individual servers or locations go down.
What limitations of individual high-availability methods does the article highlight, and how does layering address them?
The article notes limitations for each method: a single xHA backup server might itself fail; DNS protocol failover can be slow because clients wait for a timeout before trying another server; and load balancers are often managed outside the network team, reducing operational control. By layering methods—hardware failover, DNS protocol redundancy, distributed architecture, and load balancers—each technique covers the others’ weaknesses. The combined approach provides redundancy and resilience from multiple angles, reducing downtime, mitigating single points of failure, and helping meet service-level agreements.
Key takeaway
Having just one DNS server is a single point of failure. If it goes down, your network (or website) stops working. To avoid that, the article proposes a layered, “belt-and-suspenders” approach:
- Use redundant hardware (a backup DNS server that auto-takes over if the primary fails).
- Rely on DNS’s built-in redundancy (clients will automatically try another server if one doesn’t respond).
- Architect your enterprise so services are distributed (even if one location fails, other servers elsewhere continue to respond).
- Add load balancers as an extra layer of protection (they constantly monitor server health and seamlessly shift traffic if a server goes down).
Combined, these four steps form an overlapping safety net that dramatically reduces downtime and shields your network from single-point failures or human configuration errors.
DNS high availability keeps your network humming
Does your infrastructure support DNS high availability? If you have only one DNS server, what happens if it fails? Suddenly, your network stops, and your website can’t be found.
You want to be certain that your mission-critical networks can keep humming along even if that server grinds to a halt.
BlueCat buoys your enterprise’s operational performance with a comprehensive, layered approach to availability that banishes downtime.
In this post, we’ll look at why this is so important. Then, we’ll explore four avenues, that, when implemented together, create an overlapping and comprehensive solution. We’ll also delve into how these kinds of architectures work. And finally, we’ll look at how our platform can help to reduce the types of human errors that cause failures in the first place.
Welcome to disaster recovery without the disaster.
Why DNS high availability matters
Let’s say you want to visit bluecatnetworks.com. You type the URL in your web browser, and your computer or smartphone does nothing. No bueno.
You use DNS every single time you try to get somewhere on the internet. So, if bluecatnetworks.com has just one DNS server, and if that server goes down, bluecatnetworks.com becomes unreachable.
High availability aims to ensure a certain level of operational performance or uptime for a system. And the more highly available it is, the less downtime you’ll have.
You want to make sure that your presence on the internet is uninterrupted, even if a server experiences an error. This is the definition of high availability: it aims to ensure a certain level of operational performance or uptime for a system. And the more highly available it is, the less downtime you’ll have. In many cases, a service-level agreement may mandate a certain percentage of uptime.
The key is an availability configuration that is both redundant and resilient, with failover at the ready. Furthermore, it requires a solution that eliminates single points of failure associated with particular components and computer systems.
Four avenues to DNS high availability
There are four avenues to achieve high availability for DNS services. On their own, each can provide some measure of a safety net, with limitations. But implement them all (including at the hardware or software levels), and the result is a comprehensive and overlapping solution that maximizes your uptime.
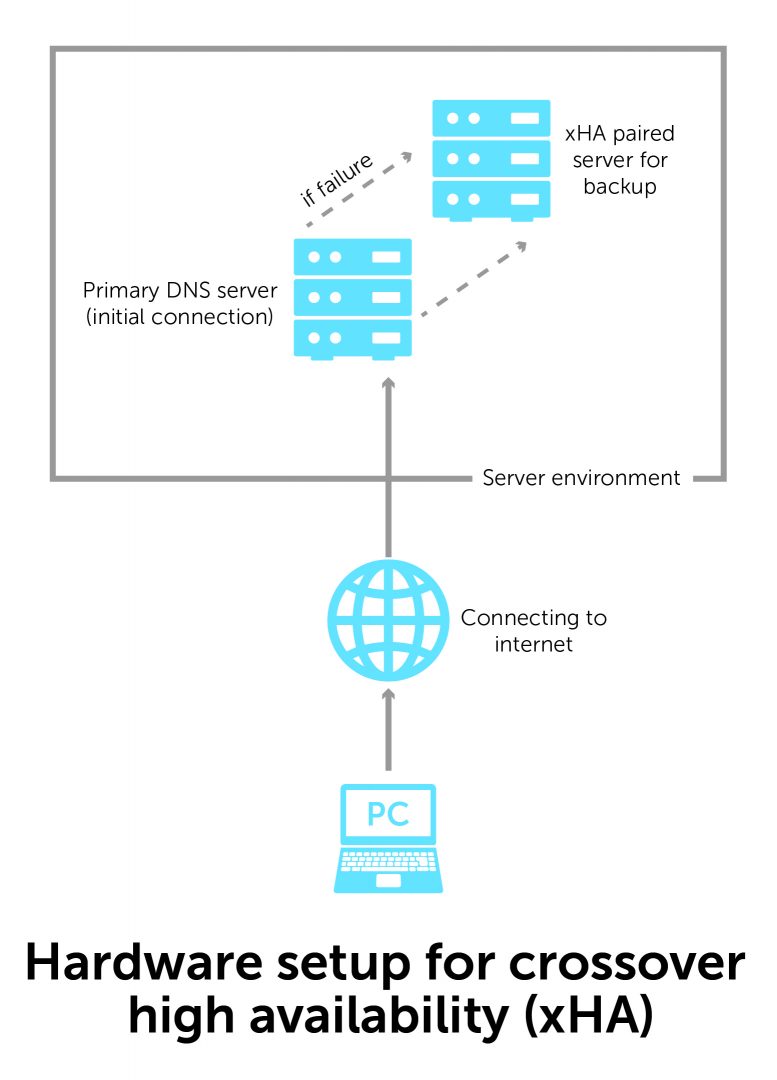
1. Hardware
It starts with building the right systems into our hardware scheme. At BlueCat, we call it xHA—crossover high availability. When the primary server fails, another backup server in the same physical location takes on the work automatically and seamlessly. This process is called failover.
2. DNS protocol
DNS itself is also inherently a redundant protocol. If one server doesn’t respond, it will purposely failover to another server instead. It doesn’t require a failure detection response from a specific server; any server will do.
3. Enterprise architecture
BlueCat architects its system components so that any server outage within it has no service impact. It doesn’t matter if a particular server is available at all. The service may have to operate from a different physical spot, but the overall service keeps running without any downtime.
4. Load Balancers
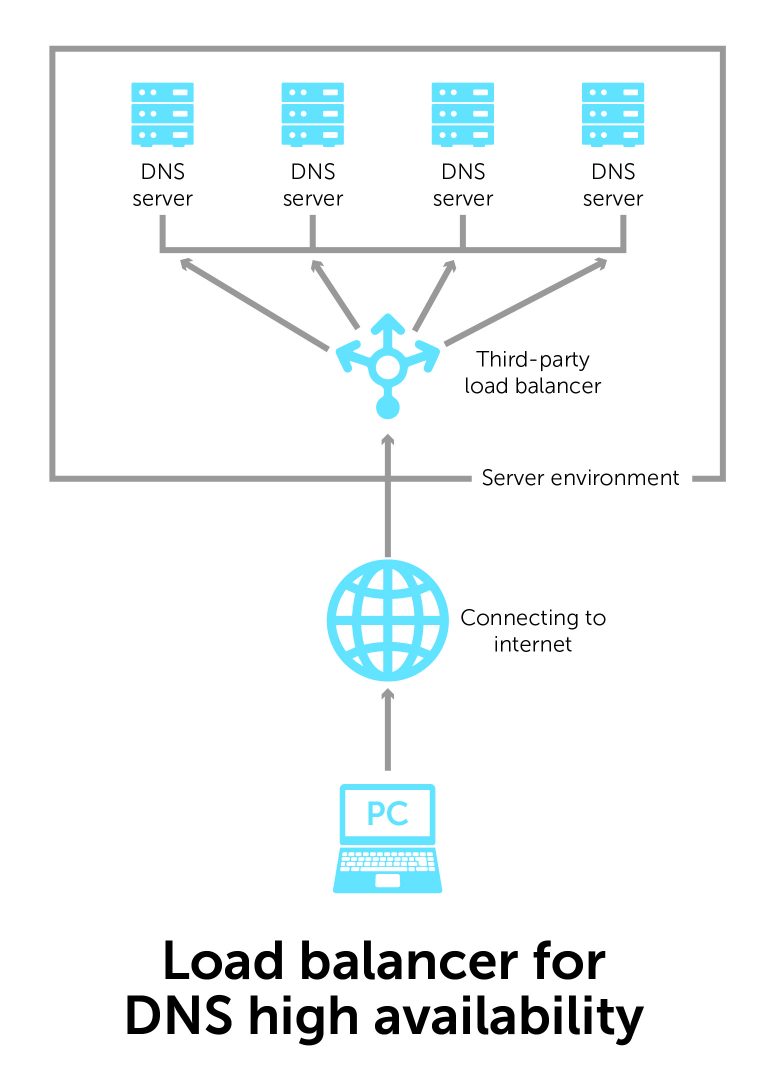
BlueCat can integrate with third-party products—load balancers, mainly—to provide an additional form of network high availability. These server load balancing products do health checks to ensure that the service is up. They switch over seamlessly in the background to another server if the service is down.
On their own, however, these solutions have limitations.
A single back-up server in an xHA pair might fail, too. The failover process for DNS protocol is slow. You have to wait for the first server to time out before it will try the second option. Load balancers are usually managed outside of your network team, leaving you with no operational control.
But implement them all, and you’ve got a layered, comprehensive approach from multiple angles. Each can cover for the limitations of the other. You can keep your network up, banish downtime, and meet your service level agreements.
How DNS high availability architectures work
How does this kind of enterprise architecture setup generally work?
The server you connect to when you enter IP addresses is your initial entry point to the network. At this entry point in the data center, we implement an xHA scheme. If that first server goes down, a secondary DNS server seamlessly takes over.
Also, a load balancing system knows about all the other servers in the enterprise. It redirects to the one most available at any given point in time.
Furthermore, when we talk about availability, we’re not just talking about servers. A server has DNS records on it. That information needs to be reachable regardless of where it resides. What happens if you make a change to it?
The BlueCat platform ensures that those records are sent to all the additional clusters of servers upstream. This allows DNS responses from anywhere in the enterprise. Each cluster knows about the others, making the enterprise truly interwoven. If any server goes down, the others can answer for it.
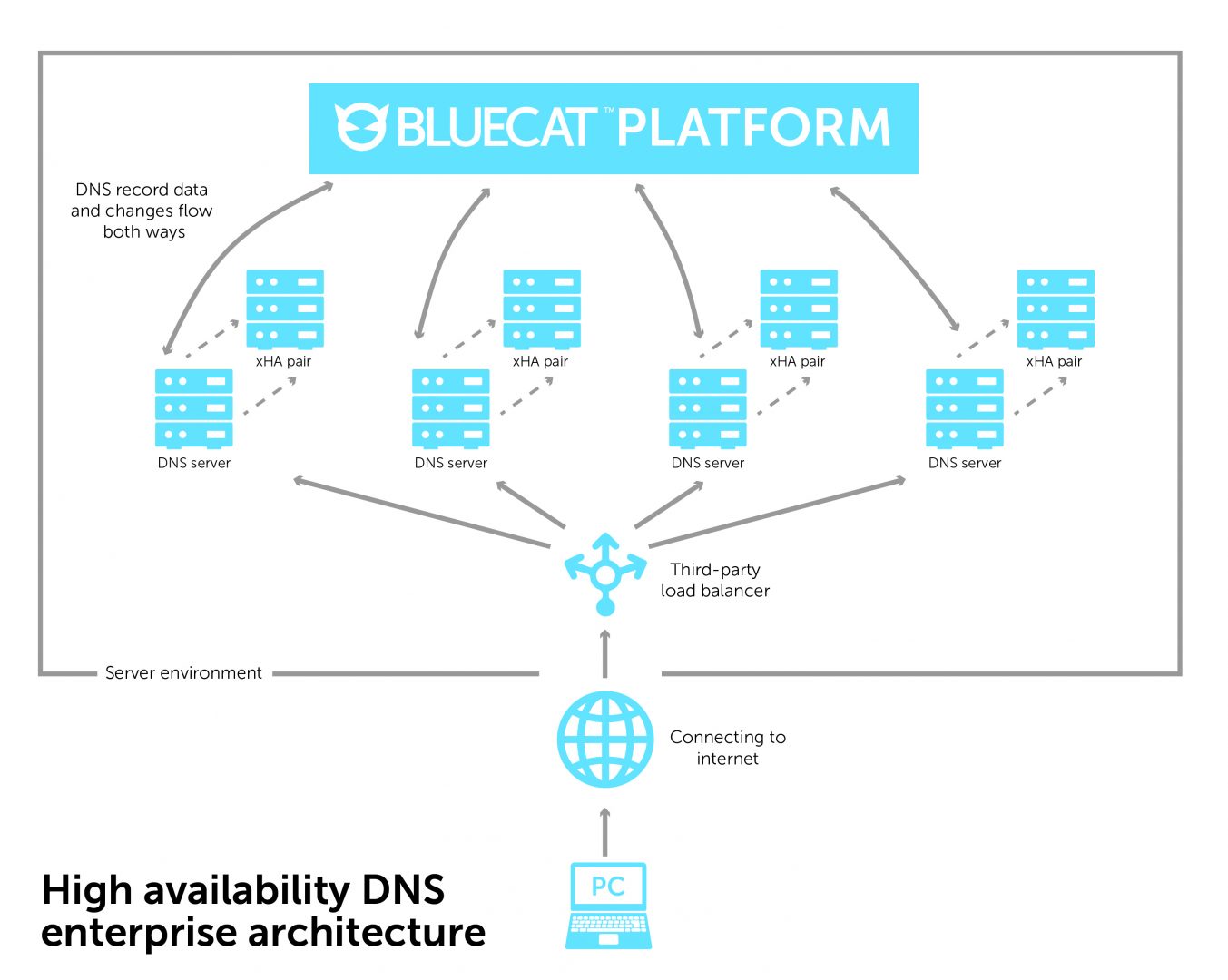
BlueCat Address Manager—our central repository of all managed DNS information on the network—sits atop this enterprise. It pushes its data downstream to all the master servers in the environment. A path from a user’s computer to the central repository exists at all times. As long as a path exists, that connection is still running without interruption, preventing data loss.
Using DNS high availability to limit human errors
Implementing this is not a catch-all parachute to protect your network from faulty implementations or changes. A mistake at the top is still a single point of failure. It will replicate downstream and lead to an outage.
However, our platform can limit what users do.
That might mean, for example, actively preventing admins from deleting everything through access or change controls. Or implementing a string of stern warnings before they do. Learn more about how the BlueCat platform can help you eliminate costly human DNS errors and keep your network running.

Rebekah Taylor is a former journalist turned freelance writer and editor who has been translating technical speak into prose for more than two decades. Her first job in the early 2000s was at a small start-up called VMware. She holds degrees from Cornell University and Columbia University’s Graduate School of Journalism.
Related content

We bet on Intelligent NetOps two years ago. Infoblox now has too.
With Infoblox acquiring Kentik, BlueCat’s CEO confirms its vision for a single platform unifying DDI, network monitoring, and observability.

BlueCat DDI data boosts Cisco Cloud Control AI-driven operations
BlueCat’s integration with Cisco Cloud Control provides AI agents with access to trusted DDI data for network investigation and remediation.

Automate your DDI modernization path by migrating with Micetro
Automate cross-platform DNS and DHCP migration with Micetro to reduce risk, eliminate manual effort, and modernize infrastructure faster.

How to map your network with user-defined links in Integrity X
Map your network with user-defined links in Integrity X to define and manage custom relationships, such as dual-stack and NAT environments.