Data Communication Platform Comparison: Apache Kafka vs. RabbitMQ vs. REST API
Before finalizing any major platform decision it is well known that extensive research must be conducted. This post highlights the process we went through before selecting Apache Kafka as our next data communication platform. We will guide you through our motivation, main data entity and requirements, which communication platforms we researched, and their differences.
A little background about Indeni’s platform to set context on our evaluation:
Indeni’s platform automates health, configuration and maintenance operations for network infrastructure devices such as firewalls, load balancers, switches.
Our services query the devices for data, parse it to a set of metrics for later to compare it against predefined thresholds and other fetched data.
Our main business data entity, “device metric”:
A device metric is composed of a set of key value pairs called “tags”, a single value representing the data point (mainly double) and a timestamp.
Object definition:
Real Data Example:
Note: Of course we have more data entities flowing between our services such as device information and alerts, however, in much lower volume.
Our scale:
Indeni’s platform scale is measured on two axis, Horizontal – the amount of network devices being monitored by our platform, Vertical – the knowledge i.e.data collection scripts we are executing per device and the set of metrics generated by them.
As for today we are collecting roughly about: 500 Million metrics a day.
Our current architecture, REST:
Until now we have used REST API to pass all our data between our services as REST has a lot of advantages such as: scalable in form of adding new endpoints and versions, idiomatic in operations (GET, POST, PUT, DELETE, etc) and resource URI, well known, easy to debug, no additional deployment complexities HW costs, the list goes on..
However REST has disadvantage where data need to be partitioned as services scaled out, message buffering is needed in some cases when incoming requests experience high peaks, data duplication in case more than one service consumes the same data, as well as losing requests in case of increased network latency or partitioning between services.
Our main requirements for the next communication platform:
Apart from being able to support our increasing scale in data we would like the following requirements from a communication platform:
- The queue should provide a reliable mechanism to transfer collected data to more than one consumer with minimal message loss and all services should see the same messages (i.e if service A consumes message M, service B must be able to consume message M as well)
- The queue needs to support back-pressure (act as a buffer for fast producer – slow consumer situations)
- Passed massages should be encrypted and clients will have to authenticate.
- Ability to dispatch a message to more than one queue / topic
- As we are an on premise solution, deployment and maintenance should be relatively simple
Which platforms we tested:
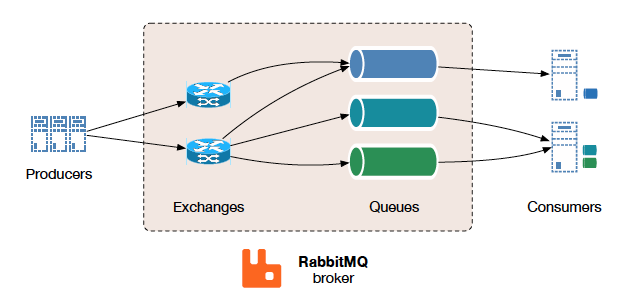
RabbitMQ:
RabbitMQ is a distributed message queue system which offers great flexibility in messages routing and delivery guarantees per single message, in addition queues can be spread and replicated across multiple nodes within a cluster for fault tolerance and high availability.
Base unit of work:
- Queue: stores messages by order, generally in memory
- Exchange: dispatches incoming messages to one or more queues by defined rules
- Binding: states a relationship between exchange and a queue
What RabbitMQ offers:
- Publishers are being acknowledged on message receipt by the broker
- Multiple consumers can subscribe to a single queue, the message broker distributes messages across all available consumers effectively load balancing the work to be done
- The broker guarantees that a message will get processed only once by a single consumer
- In order delivery guaranteed for queues with single consumer (this is not possible when queue has multiple consumers)
- When a consumer reads a message this message is not removed from the queue, but marked as read
- The consumer is responsible to Ack a message when done processing or when message accepted, once the message is Acked it will be evacuated from the queue
- A consumer can N-Ack a message marking it as available to be consumed by another consumer
- There is consumer timeout in case when a consumer does not Ack in configurable time period
- Supports persisting messages on disk for durability and reduces memory pressure
- Automatic message redelivery if consumer timeouts / fails or negatively acknowledges
What does RabbitMQ not offer:
- Each message is read only once, no message is re-read.
- In a case when more than one consumer needs to read a message this message will have to fan-out (duplicate) into multiple queues
- Cluster (mirrored / replica) queue does not participate in load, rather serves as replication in case of failure, only the master queue serves customers
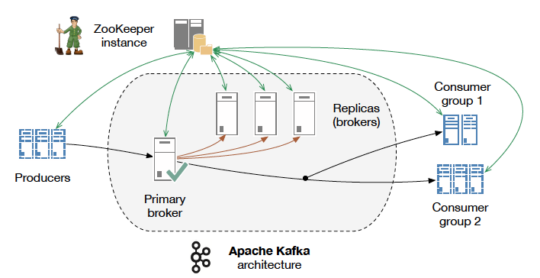
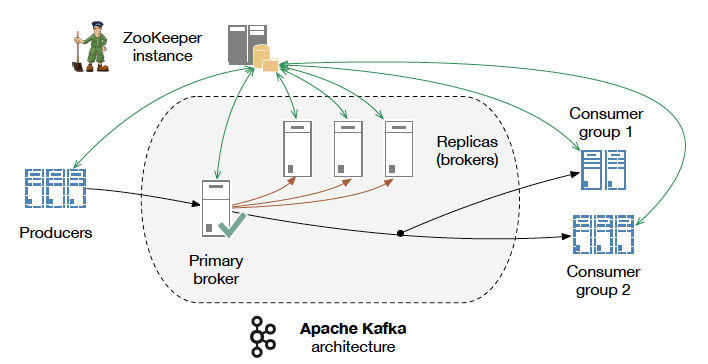
Kafka:
Apache Kafka is a scalable messaging system, designed as a distributed commit log which offers strong durability, low latency, data sharing and replication out of the box.
Base unit of work:
- Topic: a logical entity which represents a business entity and composed of one or more partitions
- Partition: an ordered log structured events list stored on disk and Kafka’s minimal parallelism component
- Consumer group: a set of one or more services, in generally same service clone
Key characteristics:
- Each partition can serve a single consumer per consumer group, meaning the ability to scale out a service is limited to a maximum of number of partitions it consumes for a topic
- Consumers can manage the read “cursor” state per partition, Kafka does provide an auto position commits and persistency in case of consumer failure
- Each message can be consumed:
- At least once: messages may be lost but are never redelivered.
- At most once: messages are never lost but may be redelivered.
- Exactly once: each message is delivered once and only once, with help of transaction involving two topics: (i) read topic (ii) offset tracking topic.
- Messages are not removed from the queue when a consumer commit-offset, rather Kafka has a configurable retention period by duration or size.
- Producers and Consumers work in batch configurable by size and time to reduce IO operations and maximize message compression
- Replicated partitions do not serve consumers but rather are used for failure recovery
- Post messages across multiple partitions and topics in a single transaction.
- On the fly stream processing to form new streams or tables
- Connectors to dump topic’s data to other systems
Key differences summary:
- RabbitMQ operates mainly in memory as an idiomatic queue while Kafka uses the disk and stores data as an event log
- RabbitMQ can support more versatile and complex architectures thanks to exchanges and bindings, where Kafka shines in its simplicity, data durability and replication as it’s designed to serve a distributed streaming platform.
- RabbitMQ and Kafka consumers interact and fetch data from a broker differently, with Rabbit consumers acting as a workers pool where each available consumer fetch a message from the head of the queue to process, in Kafka only one consumer (per group) can fetch data from a partition to process.
- In Kafka a service cluster parallelism is limited to the number of partitions as with Rabbit new server instances can be spun up and join the processing effort.
- With Kafka, the message ordering is preserved within the same partition, there is no ordering guarantees for messages in different partitions.
- With Kafka, messages remains in the broker for a defined period of time or log capacity and can be reread multiple time by multiple services, with Rabbit a message can be read only once
- Additional reads: Kafka versus RabbitMQ, RabbitMQ vs. Kafka topologies
 Images from pivotal content
Images from pivotal content
Why we chose Kafka:
As we can see from the analysis above both RabbitMQ and Kafka answer most of our requirements for scalability and reliability, however we have decided to go with Kafka since:
- Kafka’s design is more suitable for real-time data streaming pipeline
- Kafka partitions model is more suitable to our services scaling model and business requirements
- Kafka is developed in Java, and since we at Indeni are a full Scala shop it would be easier to extend, maintain, deploy and debug
- Kafka supports re-reading messages which saves us data duplication
I hope you found this post helpful. For those interested in working with technologies like Kafka, we are hiring for backend developers. Check out Indeni Careers and apply today.