Announcing the future of infrastructure health

The article announces a new platform for infrastructure health designed to reduce downtime caused largely by human error by correlating running statistics, logs, and configuration data across infrastructure components. It explains the operational problem where over 70% of outages stem from human factors—time pressure, stress, complexity, poor procedures and interfaces—and shows how the company's previous product made operators proactive by surfacing actionable insights. The platform expands that approach so partners and users can rapidly write checks (and eventually use ML-written checks) for many more device types to improve uptime across network, security, compute and storage environments.
What specific operational problem is the new platform intended to solve?
The platform targets the high rate of outages caused by human error—over 70% according to the article—by addressing the root causes operators face daily: lack of time, stress, task complexity, insufficient training and procedures, poor human‑machine interaction, and thinly staffed teams. It solves this by collecting and correlating three information streams—running statistics, logs and configurations—then using on‑board knowledge to identify issues and recommend corrective action. The result is fewer firefights, earlier detection of problems, reduced operator stress, and reclaimed engineering time for higher‑value work.
How does the new platform differ from existing monitoring, log management, and configuration tools?
Unlike traditional tools that focus on a single element (monitoring, logs, or configuration) or that aggregate data but fail to correlate it meaningfully, the platform is designed to collect all three data types and apply on‑board knowledge to identify cross‑element conditions that require attention. The article emphasizes that many solutions either do not correlate these elements or lack the domain knowledge to know what to look for. The platform enables actionable alerts that point to root causes and remediation steps, turning reactive operators into proactive teams and substantially reducing incidents before they occur.
What are the next steps for the platform and how can organizations participate?
The company has built the platform to simplify authoring of checks for new infrastructure types; writing a specific check currently takes a few hours and is planned to drop to 30 minutes within six months. Machine learning teams are also developing automated systems to generate checks. The article outlines participation paths: customers should contact [email protected], channel and technology partners via [email protected], individuals contributing knowledge at [email protected], and R&D or San Francisco roles via the respective careers email addresses. The existing product will be migrated onto the platform over the coming year, with customers able to migrate initially without write capabilities.
Today I’m excited to announce our platform for infrastructure health. Before I go into what we’ve just done, let me explain why.
What’s the current status of infrastructure health?
What exactly is broken in infrastructure operations? Why are enterprises around the world still grappling with downtime?
Our research, as well as that of others, points to the human element. Over 70% of all outages are caused by human error. This is baffling – the people responsible for running the infrastructure are some of the smartest people out there. I meet them regularly, they know their job well. Many of them have a decade or more of experience in what they do. Still, mistakes occur. Why is that?
A few years ago, the Idaho National Laboratory, which is a US Department of Energy laboratory, published a short paper regarding human error in the energy industry. It is amazing to see the resemblance between human error in different industries. They point to a few critical issues causing human error:
- Lack of time to adequately complete the task.
- Stress – physical and mental.
- Complexity of the task at hand.
- Experience and training.
- Missing or insufficient procedures and work processes.
- Poor human-machine interaction (think – user interface).
- Physical fitness (sick? tired?)
When we speak with those responsible for the smooth running of the world’s digital infrastructure, we are amazed to find out how many different components they are responsible for. For example, one admin maintains over 200 components spread over the entire US, all by herself. All she has at her disposal is a basic monitoring system that alerts her if any of the components have failed. To make matters even more difficult, some of these components have a slow internet connection and fall off the grid for no reason. Every day is a firefight for her, trying to figure out what’s broken and fix it as quickly as possible. She is stressed, operating under lack of time, high complexity, insufficient training, missing procedures, poor user interface (in some products) and is quite probably tired.
So, it’s clear why humans could make errors. The question is – how do you help them?
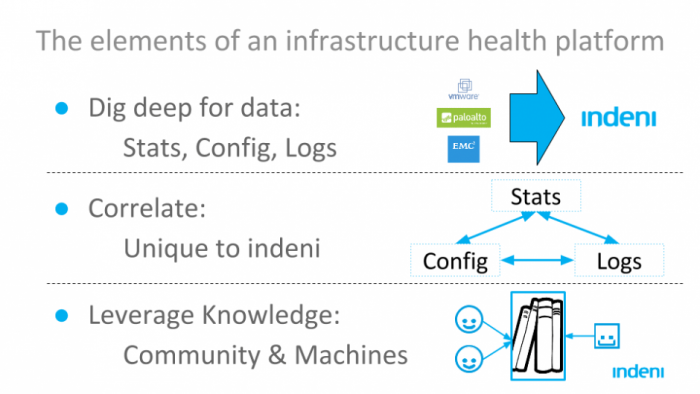
Many software companies have tried to answer this in the past: Monitoring systems, log management, and even configuration management. Unfortunately, these systems are not adequate. They don’t make a real dent in the problem of service disruption and downtime. This is due to three reasons:
- Most of these solutions focus on just one element of the health of infrastructure components – running statistics (monitoring), logs, or configuration. They don’t pull all three.
- A handful of solutions do pull in all three elements of information, but do a poor job of correlating them. Did a specific configuration cause an issue that was visible in a log that would have helped anticipate a device failure? They don’t help the user find that out. Not ahead of time and not even in retrospect.
- None of the solutions, except Indeni’s, actually know what to look for across these three elements of information. They are great at presenting the data they collect, but leave it to the (already overworked and thinly spread) human to make sense of it.
What did we do up to now?
A few years ago, the team at Indeni came up with a solution to this. We built a software product capable of pulling running statistics, logs and configs out of infrastructure components and make sense of them. The product uses its on-board knowledge to identify what requires attention and provides alerts to the user informing them of what’s needed to be done. Like one of our customers recently said: “Indeni finds stuff before it happens, and tell’s me about it.” All of a sudden, the humans operating the world’s digital infrastructure become proactive. They have a fighting chance to reduce that 70% I mentioned earlier, get it closer to zero. Another customer told me in our recent survey: “Before Indeni, my infrastructure was full of issues. I’d get calls daily. With Indeni, I barely get any calls and can handle issues before my boss knows. It freed up so much time. I’m now an architect after being an engineer previously.”
So, the experiment worked. Our technology delivered noticeable results. Customers are buying into it and are expanding their usage of the product at an average rate of 60% per year. Not only that, every single customer of ours told us we do not have competitors. Our technology is unrivaled in its ability to identify complicated issues before they occur.
Indeni tackles the main sources of human error, as described above:
- We free up time, in some cases hundreds ofman-hourss per month per person, to focus on the important projects at hand.
- We drastically reduce mental stress by solving issues before the rest of the organization knows about them.
- We reduce complexity of tasks by pointing the source of an issue and the correct course of action.
- We increase training – by pointing out issues the user has potentially never heard of in the past and showing them how to resolve them.
- We improve work processes – especially the interaction between engineering and operations teams, as well as different levels of escalation within operations teams. Information is handed off in a smoother way.
- We watch the admin’s back – so if they’re making a critical change at 2AM, due to maintenance window constraints, we’re there to identify if a mistake was made by a tired admin.
But, all this was limited to Check Point firewalls, Cisco switches, F5 load balancers, and Palo Alto Networks firewalls. That’s a small subset of the entire world’s infrastructure.

Time to expand
A single company, no matter how big, can never tackle the problem of covering all of the possible types of infrastructure components on its own. The world is vast. Trillions of dollars worth of equipment is deployed out there. It’s impossible to even imagine how big it is.
So, we decided to build a platform. We’ve taken all of our expertise and know-how pertaining to how to correctly collect the three elements of data (running statistics, logs and configuration) and correlate them. We built a robust platform full of the capabilities we ourselves needed to build our first product. It is complicated on the inside, but the beauty of it is the simplicity with which one could write on top of it. Today, writing a check for a specific possible error for a specific infrastructure component type will take less than a few hours on our new platform. Over the next six months, we’ll shorten that to 30 minutes.
In addition, our machine learning team is building automated systems capable of writing their own checks on top of the same platform. Computers writing code! Mind boggling.
This means that on top of our platform, the world will now be able to write highly intelligent checks for any piece of infrastructure out there. Whether privately owned, or part of the public cloud.
With our platform, human error in infrastructure operations will be a thing of the past.
Our end goal
Our goal is to have all of the world’s largest enterprises use our platform to ensure the uptime of their entire infrastructure – network, security, virtualization, compute, storage and more. To get there, we will be working closely with our customers, our partners and the wider community. This is a global effort and we’d love for you to join us by emailing the relevant contact below:
- Customers – [email protected]
- Channel (VAR/VAD/DMR) and technology partners – [email protected]
- Individuals looking to contribute knowledge on top of the platform – [email protected]
- Talented R&D engineers looking to join our team in Israel – [email protected]
- Sales reps, SEs, support engineers and IT experts looking to join our team in San Francisco – [email protected]
With all of us working together, infrastructure operations will never be the same.
FAQ: What happens to the current product?
The current product, capable of identifying issues in Check Point firewalls, Cisco switches, and other devices, will be migrated to operate on top of the platform over the coming year. Existing customers will be able to migrate to the platform, initially without the ability to write on top of it. If you are an existing Indeni customer and are interested in working with the platform, please reach out to your Indeni contact person.
Related content

BlueCat moves agentic AI from insight to action with new AI integrations
Extends its Intelligent NetOps platform to help organizations unlock measurable AI value through a unified data foundation

BlueCat appoints Jeff McCullough as Vice President, Worldwide Channel and Alliance
Experienced channel leader will drive partner-led growth and support partners in generating revenue and value within BlueCat’s global ecosystem

BlueCat introduces BlueCat Horizon, a SaaS-first Intelligent NetOps platform for cross-domain network operations
The platform delivers a unified control plane for DNS, DHCP, IPAM, security, and observability, empowering rapid, automated action across networks

Fewer than half of enterprises are fully successful with network observability tools
Fragmented tools and cloud blind spots are straining NetOps, but a new five-stage maturity model charts the path to excellence.