Are your DNS servers still architected like it’s 1999?
DNS hasn’t changed much, but networks have. Your traditional DNS server architecture might be due for some re-thinking to a cascading approach.

The article examines traditional primary-secondary DNS architectures and argues they are becoming outdated compared with a cascading replication model that better suits modern, large-scale networks. It explains the real-world problem of single-primary bottlenecks, failure domains, and scaling limits that cause delayed updates and manual recovery, and contrasts this with cascading replication that distributes updates across regional or zone primaries to reduce latency and improve redundancy. Key outcomes discussed include faster replication at scale, zonal partitioning for locality, and zero-touch self-healing that minimizes global impact from single-server failures.
What are the main limitations of the traditional primary-secondary DNS server architecture described in the article?
The article identifies several limitations of the traditional primary-secondary model: a single primary server is a critical point of failure—if it faults, manual intervention is typically required to restore full functionality; scaling is constrained because the primary must serve all secondaries in parallel, which increases compute load and degrades performance as the number grows; and there are capacity limits—BlueCat modeling shows performance degradation when a primary serves more than 20 secondaries, and BlueCat recommends no more than eight secondaries. These issues lead to slower replication and larger failure domains in bigger environments.
How does cascading replication improve update times and scalability for large numbers of DNS servers?
Cascading replication reduces total replication time and improves scalability by creating multi-hop distribution paths so each node replicates to a limited number of downstream servers. For example, with 65 servers where a primary can update 20 in parallel, replication serially across three waves takes 35 seconds; in a cascading model where each node has up to eight secondaries, the primary updates eight servers in 10 seconds and those eight update their leaves in the next 10 seconds, finishing in 20 seconds. As server counts grow, this branching approach yields larger time savings and avoids overloading a single primary because replication work is distributed across the topology.
What operational advantages does a cascading DNS architecture provide beyond faster replication?
Beyond reducing replication latency, the article highlights operational advantages such as easier zonal or regional architectures—each zone can have its own primary so updates propagate locally first and globally later, aligning with locality needs. Cascading enables self-healing and zero-touch auto-recovery: predefined multiple upstream options allow servers to automatically switch to alternate paths if an upstream fails, maintaining updates without human intervention. It also reduces global impact from a single primary failure by confining outages to a zone and permitting quick reassignment of that zone to another primary, while still ensuring clients receive needed DNS information via alternate paths.
While technology has drastically evolved in the last 33 years, many DNS server architectures today follow the same networking rulesets and ideas that were cutting edge in 1987. Until about 1999, all of those rules were more or less unchanged when DNS extension mechanisms were introduced.
Is your DNS still architected like it’s 1999?
Even if it is, why change what you’ve always been doing? It’s not wrong—it’s obviously working. But the internet of 1999 is about as relevant today as its breakout star of that year, Napster.
A lot has evolved since then.
This post will explore the traditional primary and secondary DNS server architecture. And it will delve into why it might be due for a redesign to a cascading approach that better reflects today’s networking capabilities.
A small group of IT professionals who are part of our open DDI and DNS expert conversations recently discussed these ideas. All are welcome to join Network VIP on Slack.
Primary-secondary DNS server relationships
In a traditional DNS server setup, one primary DNS server feeds all the secondary servers in your environment. It’s an architecture that has worked for a very long time, especially for any small environment. However, there are drawbacks.
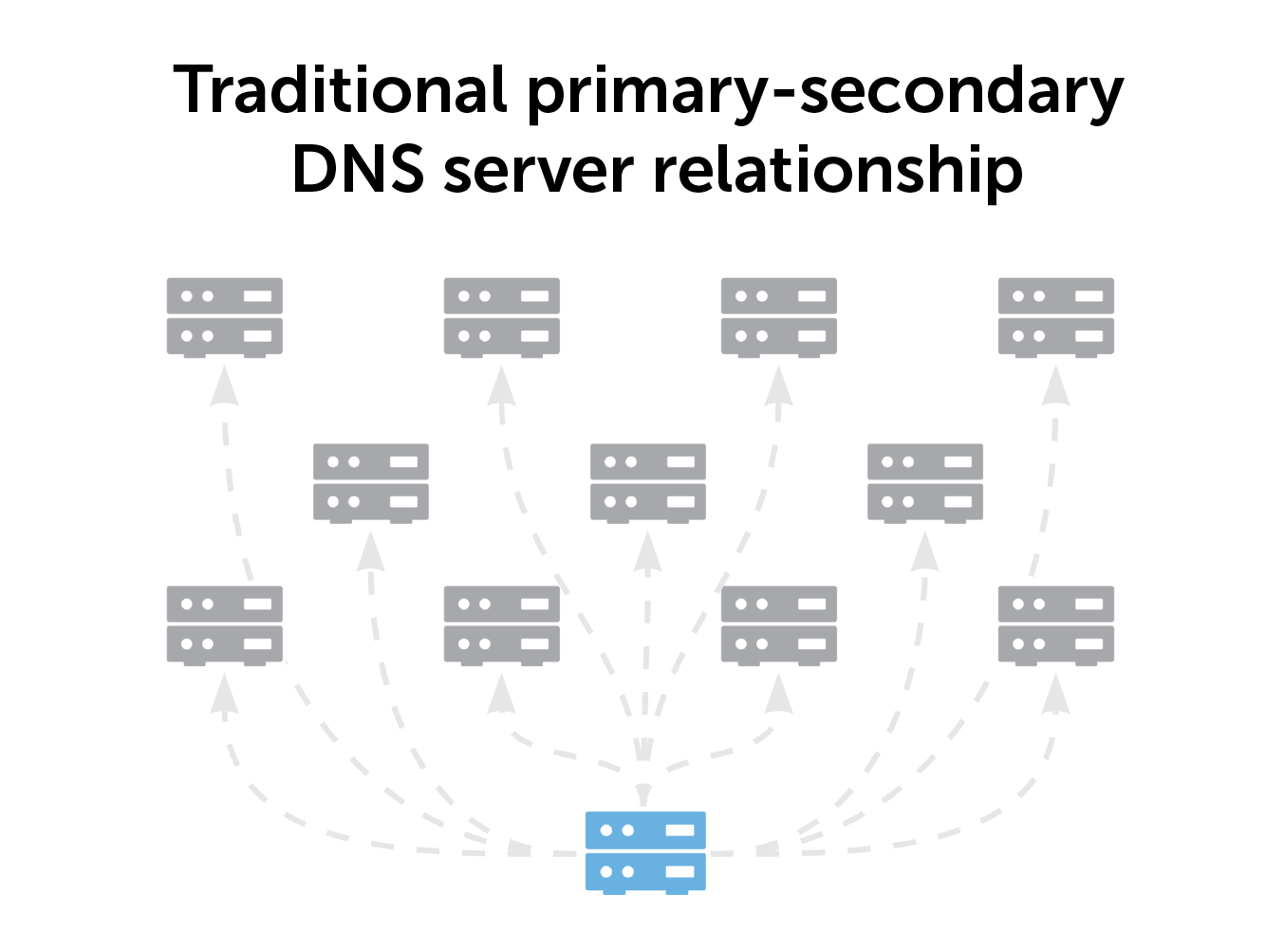
If the primary server faults, everything is lost. There are copies of DNS records in the secondary servers. But bringing the primary server up again requires manual intervention.
Furthermore, there are capacity limitations. Connecting the primary server to more secondary servers requires more computing power. BlueCat modeling shows that connecting more than 20 secondary servers to your primary server degrades performance. BlueCat doesn’t recommend any more than eight secondaries.
Cascading replication as a DNS server alternative
With a cascading architecture, everything replicates to every server. You can have a spider web or tree branch type of cascade with multiple paths and redundancies.
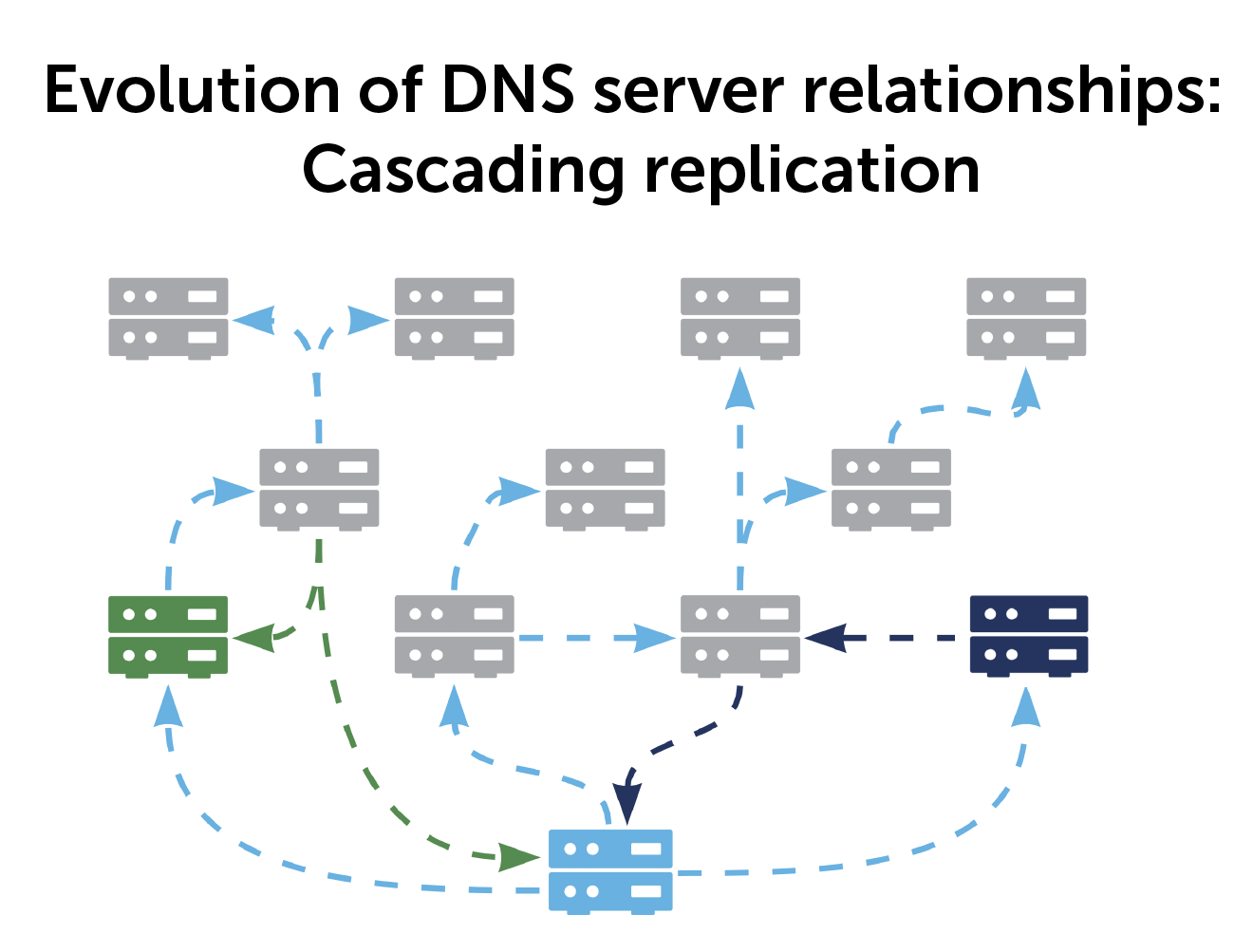
Imagine a network with 65 DNS servers. You want to replicate them, and the primary server can do 20 servers in parallel. If one synchronization takes 10 seconds, the first 20 servers get updated in 10 seconds. The second 20 get updated in another 10 seconds, then another 10 seconds for the third, and finally the last five. In total, that’s 35 seconds.
Now, take a cascading replication for those 65 servers. A primary has a maximum of eight secondaries (or leaves). The primary updates eight servers in 10 seconds, but then each of those eight can replicate eight of its own leaves in 10 seconds. Replicating finishes in 20 seconds.
While there’s not much of a difference between 20 and 35 seconds, imagine if you had hundreds of servers. The timing differences become significant.
The benefits of a cascading model
With a cascading model, it’s also easier to architect your network into zones or regions. No one central server is responsible for the whole world. Updates do not have to go back to the central server and then propagate out from it.
Think of it instead as one primary server per zone. It could be the same primary for multiple zones, sure. But the idea is to split out various zones to various servers across multiple data centers.
For example, let’s say you have servers in Germany, Japan, and the U.S. And someone registers a web server in Japan. Does Germany and the U.S. need to know about that registration immediately? Probably not. That server is primarily important for the local Japan zone. So, make your updates there first and then propagate from there throughout the globe.
And another thing: Self-healing
Self-healing architecture in DNS is not common, but a cascading architecture makes it possible.
If a server goes down, you have architected and pre-defined the secondary options of communication. As a result, the server needs no human intervention. The moment a server goes down, the server will automatically switch over and the system self heals. It’s zero-touch auto heal.
Why do it this way?
The primary benefit of a cascading model is better redundancies.
In case of a server failure, you bypass it by specifying multiple upstream servers. You can tell any server, ‘this is your primary, if you can’t reach it, try another one.’ You can create secondary, tertiary, and quaternary paths—up to 256 different upstream abilities. As long as one server in your path is working, you can still keep your system up to date.
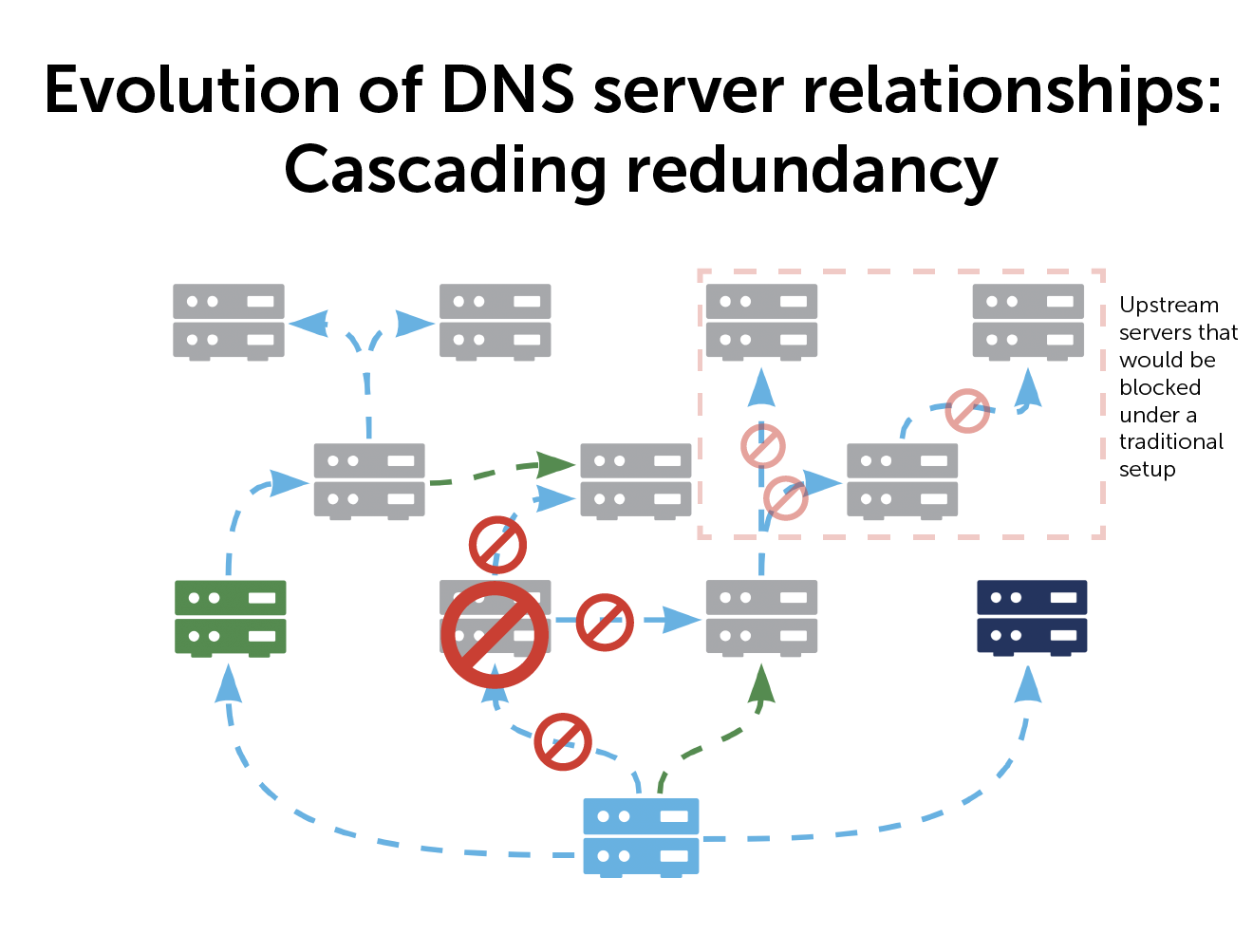
If your primary server goes down it is just for that zone, minimizing the impact on your global network. And you can move that zone to any other primary server to keep things humming. Every one of your clients and servers is still getting all the information, just via a different path.
All of this is to not say that a cascading architecture is right for everyone. If your network is small, a traditional primary-secondary architecture may be exactly what you need. The larger your enterprise, the more benefits you will reap from a cascading model.
However, if your DNS server architecture might need some updating, learn how the BlueCat platform can help.
Published in:

Rebekah Taylor is a former journalist turned freelance writer and editor who has been translating technical speak into prose for more than two decades. Her first job in the early 2000s was at a small start-up called VMware. She holds degrees from Cornell University and Columbia University’s Graduate School of Journalism.
Related content

We bet on Intelligent NetOps two years ago. Infoblox now has too.
With Infoblox acquiring Kentik, BlueCat’s CEO confirms its vision for a single platform unifying DDI, network monitoring, and observability.

BlueCat DDI data boosts Cisco Cloud Control AI-driven operations
BlueCat’s integration with Cisco Cloud Control provides AI agents with access to trusted DDI data for network investigation and remediation.

Automate your DDI modernization path by migrating with Micetro
Automate cross-platform DNS and DHCP migration with Micetro to reduce risk, eliminate manual effort, and modernize infrastructure faster.

How to map your network with user-defined links in Integrity X
Map your network with user-defined links in Integrity X to define and manage custom relationships, such as dual-stack and NAT environments.