My Network Automation Journey, Part 1: Frameworks and Goals
Successful implementation of network automation requires planning, clear goals, and a strong deployment strategy. Blog series part 1: plans and goals.

BlueCat invited John Capobianco, author of “Automate Your Network: Introducing the Modern Approach to Enterprise Network Management” to walk us through his journey of network automation. From the planning phase to deployment up the stack, John will cover the tradeoffs and critical decision that every network automation project should address – including the role of DNS. John’s opinions are solely his own and do not express the views or opinions of his employer.
Network automation. Most administrators and engineers would love nothing more than to automate their network…someday. Yet it always seems to be one of those “strategic projects” that never gets off the ground.
Why? There are almost too many excuses to mention. “We really aren’t doing too many manual tasks.” “The right network automation tools are not yet available.” “Network configuration management is too time consuming, even with an automation platform in place.” “Our network engineers aren’t trained in automation frameworks; we’re used to running our network services through the command line interface.” “Our network operations are just built on the premise of human intervention – we don’t have the type of network which lends itself naturally to automation.” “Software defined networking and virtual networks are the cloud team’s responsibility – we just work here.” And so on.
I get it. I was once one of these network administrators. Roughly two years ago, I was introduced to Ansible and it changed my entire outlook, methodology, and, at the risk of sounding dramatic, life itself.
This entry is the first of a multi-part series reflecting on my two-year journey and transformation from a traditional network designer and administrator to a modern network developer. I’ll highlight my major learnings and cover the evolution from basic one-time changes to full configuration management and network infrastructure as code.
Before automation: challenges
Let’s start with a quick look at the “before” state. As a senior IT planner and integrator for a large public-sector agency with a large and complex nationwide network, I am responsible for designing and implementing changes in an environment of increasing complexity.
The network I manage was quickly becoming a process bottleneck, hindering agility on several projects. One larger project involved updating a QoS model at the access layer of the network. This involved updating over 300 devices manually! Changes at scale often posed the greatest challenge and required the longest development cycle. Even if the core fixes were relatively simple, accurately distributing the changes was a heavily manual process – following scripts at the CLI of each device, updating configurations one device at a time.
Finally, a large and complex network change “broke” our system. A new data center was being integrated into the network, which meant foundational routing configurations on the campus would need to change. Once we tallied up the manual effort required to implement the change and the outage window, we decided that automation couldn’t wait any longer.
Before automation: the toolkit
Due to both the scale and complexity of the networks I deal with, learning and implementing network automation through a pre-determined framework was a necessity. It was evident the traditional (legacy?) methodologies I had been using were quickly becoming antiquated. I could no longer maintain an enterprise network manually. I chose Ansible as the most accessible option – I wanted quick wins.
Let’s take a step back and talk about the requirement checkboxes Ansible ticks off as an automation solution, and how I ended up ultimately selecting Ansible as my toolset of choice.
- Agentless
- Nothing special to configure on my devices to allow Ansible interact with them
- Secure
- Ansible uses the Secure Shell (SSH) protocol to connect to the network infrastructure being automated
- Cost-effective
- Ansible is free with an option for for support with an enterprise license
- Ansible can run on any Linux distribution including, Ubuntu and CentOS (which are also free)
- Ansible can also be run on supported licensed Red Hat Enterprise Linux
- Accessible
- The solution did not have to be ‘simple’ but needed to be flexible
- It turns out Ansible can be as simple or as complex as required
- Solution complexity can increase in time as you become more familiar with the framework
It is important to clearly distinguish the fact the Ansible is not a programming language. This is not Java or C++ for the network. Ansible is a framework written in Python, but you do not need to know Python to use Ansible. Let’s cover the framework:
- Inventory:
- Static ini file
- Possibly dynamic using API calls to NMS, IPAM, or inventory system already maintained with a list of network devices
- Variables:
- group_vars
- host_vars
- YAML format
- Data models for network devices as a group and as individual devices
- Playbooks:
- YAML file format
- Serial execution of tasks
- Calls Ansible modules
- Templates:
- Jinja2 file format
- Dynamic calls to the variables at playbook run time.
- Mix of static text, simple logic (“if”, “else”, “for”), and variables
- Plug-ins:
- Python format
- Extend base capabilities of core Ansible engine
- Custom written
- Modules:
- Python and PowerShell format
- Vendor specific modules for communicating with devices
Once you get a handle on how the Ansible tools work, you can move onto making tactical changes to the network in the form of one-time playbooks. Building and evolving on your success, full automated configuration management and CI/CD can be implemented as a final advanced step. In my case I jumped directly into automating changes on the network due to the scale and complexity of my change.
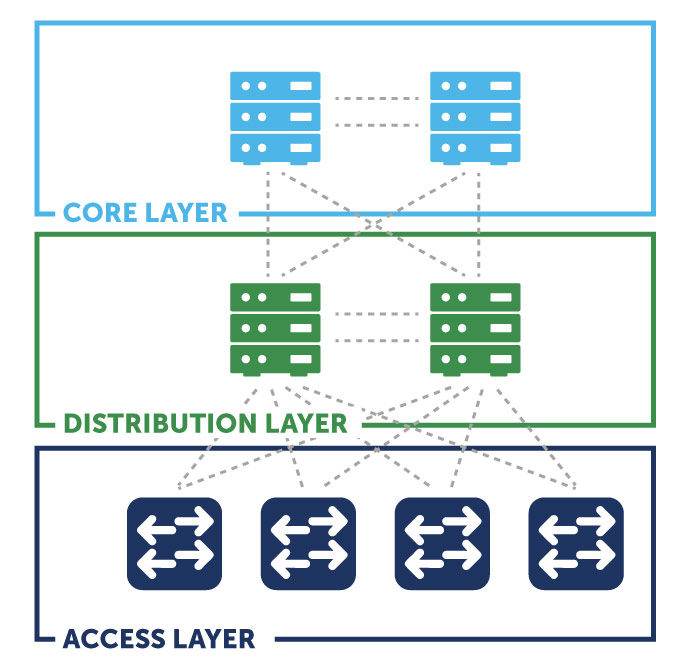
Some network projects require complex changes at a very large scale. My particular project required changes at the Core and Distribution layer across the entire enterprise. In addition to the global routing table, all of our virtual route forwards (vrfs) needed to be changed to accommodate a new data center.
The specifics are not important, but the changes, if not handled correctly, could impact the entire network at the Core and Distribution layers. The blast radius of this particular change could “blackhole” (make inaccessible) entire buildings from the campus. As soon as the first distribution layer device changed, it would be offline until the last distribution layer device was completed – a necessary step to proceed to the matching required changes at the Core.
It was decided early on that the Core changes, for now, would be performed manually at the CLI. In retrospect, these changes could have also easily been automated.
Goals of network automation
Our goals, which would develop into the framework for our process, were simple:
- Minimize downtime
- Quickly, but efficiently and with quality, complete the change
- Avoid errors and standardize the deployment across each distribution layer device
- Avoid having to visit any location to restore connectivity via console cable
- Capture pre-change state
- OSPF Information
- Global routing table and per-vrf
- Routing tables
- Neighbors and adjacencies
- Running-configuration of each device
- OSPF Information
- Make changes at each Distribution switch
- Create and distribute desired state configuration file
- Update configurations using the Cisco config-replace methodology
- Make changes at Core
- Using standard configuration commands
- Not using config-replace methodology
- Capture post-change state
- Same information that was captured during pre-change state
- Used for comparison / differentials / validation of new network state
- Using standard configuration commands
Some of our goals turned out to conflict with one other. For example, we wanted to limit downtime but also wanted to capture information from each device before the change. If we were performing this phase manually it meant setting up putty logging sessions to individual files per CLI session, adding a great deal of time to the process. Also, the majority of the steps were repeatable commands on each device with very little changing on each device. This was the perfect opportunity to automate.
In retrospect, my first automation task – replacing the running-configuration across the entire campus distribution layer – was ambitious for a beginner. My advice is to start by automating the collection of information from the network and not jump directly into making changes with the tool. Simple collection of information is non-intrusive. It allows administrators to get used to the Ansible framework before implementing any changes to the network.
In my next post, I’ll talk about my first steps applying the Ansible-based framework to the network.
John Capobianco describes his two-year journey from traditional network administration to modern network automation using Ansible, motivated by large-scale manual change challenges in a complex nationwide public-sector network. He explains the real-world problem of time-consuming, error-prone manual changes (for example, updating QoS across 300+ devices and integrating a new data center) and how Ansible’s agentless, SSH-based, cost-effective, and accessible framework met the technical requirements for inventory, variables, playbooks, templates, plugins, and modules. The article outlines operational goals—minimize downtime, avoid errors, capture pre- and post-change state, and standardize deployment across distribution and core layers—and recommends starting automation with non-intrusive data collection before moving to configuration changes.
Why did John choose Ansible for network automation instead of other tools or building a custom solution?
John selected Ansible because it met several practical requirement checkboxes for his large, complex enterprise network. Ansible is agentless, requiring no special configuration on devices, and uses SSH for secure connections. It is cost-effective—free with an optional enterprise support license—and runs on common Linux distributions. Ansible is accessible: it can be simple or complex as needed, and does not require learning a new programming language to get started. The framework’s inventory, variable, playbook, template, plugin, and module constructs provided the flexibility and scalability he needed for tactical changes and later full configuration management.
What were the main operational goals and tradeoffs John identified for his automation project?
John’s primary operational goals were to minimize downtime, complete changes quickly and with quality, avoid errors, standardize deployment across distribution layer devices, and capture pre- and post-change state for validation. He also aimed to create and distribute desired-state configuration files and use Cisco config-replace for distribution switches while applying standard commands at the core. He noted tradeoffs: for example, capturing pre-change data increased time and could conflict with the desire to reduce downtime. These conflicting goals informed his process decisions and led to the recommendation to begin automation with non-intrusive data collection to reduce risk.
What practical advice does John give for teams starting network automation with Ansible?
John advises starting automation by automating information collection from the network rather than immediately performing configuration changes. Collecting data (OSPF info, global and per-vrf routing tables, neighbors, adjacencies, running configurations) is non-intrusive and helps teams become familiar with Ansible before making changes. He cautions that jumping directly into large-scale config replacements can be overly ambitious for beginners; instead, gain initial wins with safe, repeatable tasks and then evolve toward full configuration management and CI/CD as confidence and capability grow.
Published in:

John Capobianco is the Senior IT Planner and Integrator for the House of Commons, Parliament of Canada. He is a 20-year IT professional who has fallen in love with automation and infrastructure as code. John maintains his CCNA, 2x CCNP, 5x Cisco Specialist, and Microsoft Certified ITP: Enterprise Administrator while continuously developing his programming and automation skills. He authors books and an automation-themed blog, automateyournetwork.ca. Find him on Twitter @john_capobianco or LinkedIn /john-capobianco-644a1515.
Related content

We bet on Intelligent NetOps two years ago. Infoblox now has too.
With Infoblox acquiring Kentik, BlueCat’s CEO confirms its vision for a single platform unifying DDI, network monitoring, and observability.

BlueCat DDI data boosts Cisco Cloud Control AI-driven operations
BlueCat’s integration with Cisco Cloud Control provides AI agents with access to trusted DDI data for network investigation and remediation.

Automate your DDI modernization path by migrating with Micetro
Automate cross-platform DNS and DHCP migration with Micetro to reduce risk, eliminate manual effort, and modernize infrastructure faster.

How to map your network with user-defined links in Integrity X
Map your network with user-defined links in Integrity X to define and manage custom relationships, such as dual-stack and NAT environments.